News
VLOGGER: the new AI model from Google capable of creating moving avatars
AI is still in development, but it shows promise.
- March 26, 2024
- Updated: July 1, 2025 at 11:51 PM
A group of researchers from Google has created VLOGGER, a new artificial intelligence tool that takes a still image and is able to turn it into an animated and controllable avatar. This is a video generation approach that is somewhat different from Sora, from OpenAI, but it could have many applications.
VLOGGER is an AI model capable of creating an animated avatar from a still image and maintaining the photorealistic appearance of the person in the photo in each frame of the final video. Similar things can already be done to some extent with tools like Pika Labs’ lip syncing, but this seems to be a simpler option that consumes less bandwidth.
The model also takes an audio file of the person speaking and controls the movement of the body and lips to reflect the natural way that person would move if they were the one saying the words. This includes creating head movements, facial expressions, gaze, blinking, as well as hand gestures and movements of the upper body without any reference beyond the image and audio.
Currently VLOGGER cannot be tested, as it is nothing more than a research project with several demonstration videos, but if it ever becomes a product it could be a new way of communicating in team collaboration apps like Slack or Teams.
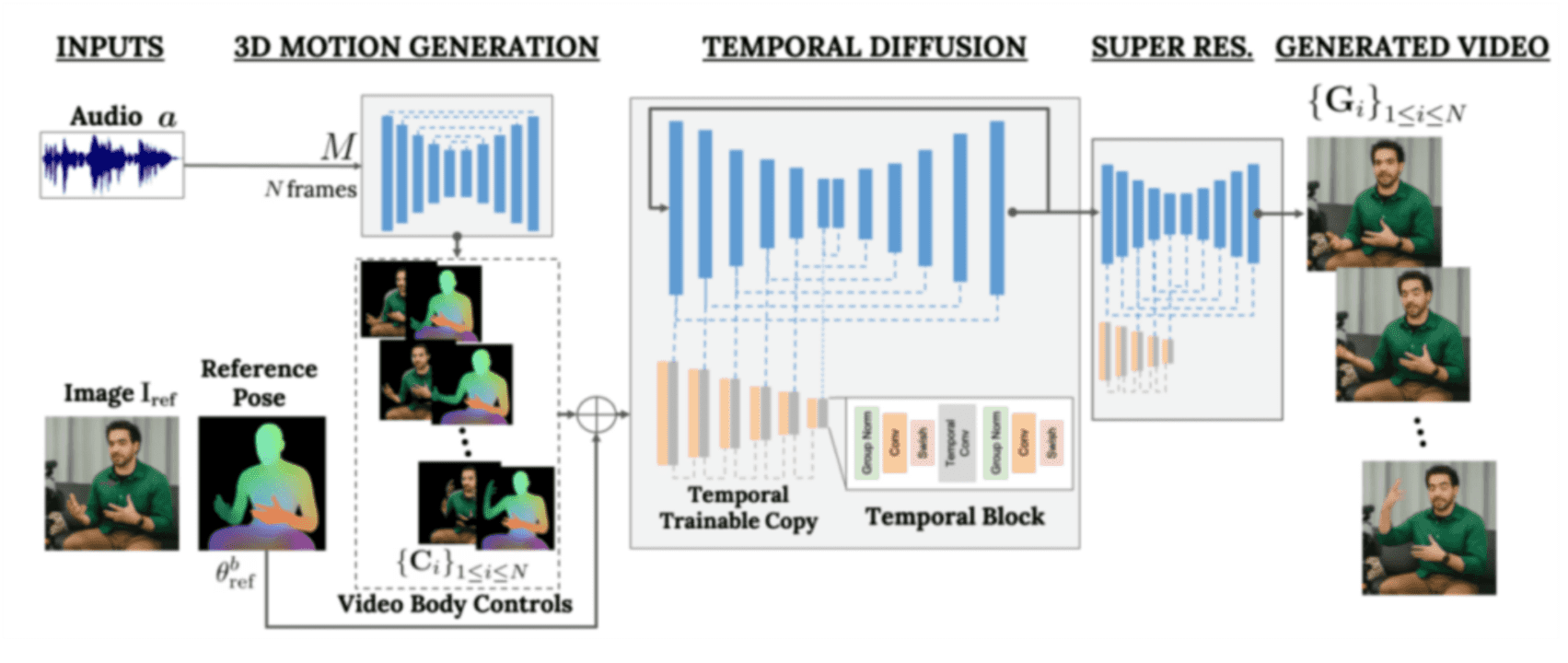
VLOGGER is based on the broadcast architecture that drives text-to-image, video, and even 3D models, like MidJourney or Runway, but adds additional control mechanisms. To generate the avatar, VLOGGER follows a series of steps: first, it takes the audio and image as input data, subjects them to a 3D motion generation process, then to a “temporal diffusion” model to determine timing and movement, and finally scales up and converts it into the final result.
To train the model, a large multimedia dataset called MENTOR was needed, which contains 800,000 videos of different people speaking with each part of their face and body labeled at every moment.

Publicist and audiovisual producer in love with social networks. I spend more time thinking about which videogames I will play than playing them.
Latest from Pedro Domínguez
- The Spirit of Giving: How to Donate Safely Online This Christmas
- Black Friday Scams: How Avast Scam Guardian Protects You from Fake Deals in Real Time
- Working from home? Find out what you need to know to keep your devices safe
- Fraudulent Websites Are on the Rise: Here’s How Avast Free Antivirus Keeps You Safe
You may also like
 News
NewsChatGPT achieves a 76% increase in its performance
Read more
 News
News'Clair Obscur: Expedition 33' cost a complete fortune, but it's wildly successful
Read more
 News
NewsHelldivers 2 is getting ready to receive its biggest update to date
Read more
 News
NewsThe Game Awards crowned the game of the year last night amid huge controversies
Read more
 News
NewsThe most shocking news from The Games Awards 2025
Read more
 News
NewsThe series returns where you will see Idris Elba like you have never seen him before
Read more